生成AIは、さまざまな領域の業務に大きな影響を与えている。中でも早くから生成AIの恩恵を受けそうなのが、サポートセンターやカスタマーセンターなどの問い合わせ対応業務だ。アシストでは、自社が扱う生成AIベースのSaaS型インサイトエンジン「Glean」を用いて、顧客向けのサポート業務の変革に取り組んだ。
サポート業務は生成AIで変革できる
アシストは、国内外のさまざまなソフトウェアの活用を通じて、顧客のビジネスを支援している。多様なソフトウェアを提供するアシストでは、生成AI技術を活用したサポート業務の改革を検討し、いち早く検証を開始した。少ない人数で効率的にサポートのサービスを提供するために、ChatGPTのような技術が使えると考えたのだ。
アシストは2023年3月から生成AI活用の検討を開始し、5月にはプロジェクトを発足させた。このプロジェクトでは、サポート業務の効率化と高度化を目標に掲げた。サポートチームとAI技術チームを中心に、情報システム部やセキュリティ委員会なども参加する形でプロジェクトはスタートした。対象としたのは、サポート業務への生成AIの適用で、まずはChatGPTの活用を検討した。

ChatGPTの回答精度を確認するために、FAQ(よくある質問とその答え)の情報を用いたユーザー問い合わせ対応業務で検証を行った。「FAQを使い回答できる対応は、それほど難易度は高くありません。そのレベルの質問に対し、ChatGPTではどれくらいの回答精度になるかを試しました。結果は良好と判断できました」と言うのは、アシスト サポートサービス技術本部 DX推進サポート部 課長の平 拓郎氏だ。
良好な結果を受け、検証対象を拡大し、複数製品のサポート業務でさらに検証を行った。その結果、製品により回答精度にばらつきがあることが判明する。「インターネット上に製品に対するナレッジ情報が多いかどうかで、回答精度のばらつきが大きいことが分かりました」と言うのは、アシスト サポートサービス技術本部 DX推進サポート部 課長の土井淳史氏だ。
回答精度のばらつきの他にも、社内における生成AI利用ガイドラインの未整備が課題として浮上した。多様な業務での活用を想定し、セキュリティやガバナンス確保のためのガイドライン整備が急務となり、これは別チームが担当することとなる。

ファインチューニングも効果なし、生成AI活用プロジェクトは一時頓挫
ChatGPTの回答精度の具体的な検証の方法は、スプレッドシートに入力された質問に対し、ChatGPT APIを用いて生成AIが回答を生成し、回答欄のカラムに出力する仕組みを構築して実施した。これを使いLLMはGPT 3.5、その後は4.0でも検証している。
製品担当者は生成された回答を見て、顧客に対しそのまま回答を出せるレベルか、内容が間違っているのかなどを判断し、回答精度を100点満点で評価した。アシストのサポートチーム(約200名)は、年間約4万件の問い合わせに対応しており、検証で評価した質問の数は620件だ。その結果、インターネット上にナレッジが多い製品では回答精度が高かった一方で、ナレッジが少ない製品では回答は実用レベルに達しなかった。
アシストの取り扱い製品は多岐にわたり、インターネット上のナレッジ量もさまざまだ。ナレッジの質と量により、回答精度に大きなばらつきが生じることが確認されたのだ。そこで、ナレッジ不足による回答精度低下の課題を解決するために、次のステップではFAQの情報を基にファインチューニングを実施する。
当時はRAG(Retrieval-Augmented Generation)などの手法は、まだ一般的ではなかった。RAGは、ベクターデータベースとセマンティックサーチで関連情報をLLMに提供することで生成される回答をコントロールしハルシネーションなども減らす仕組みだ。
FAQから質問と回答をセットにした、JSO形式の学習データを用意した。それを用い、ファインチューニング実施したが、回答精度はなかなか向上しなかった。当時利用可能なモデル(GPT2.0など)が古かったため、チューニング済みのモデルよりも新しい汎用モデルのほうが高精度だった。
その後、新しいモデルも利用できるようになったが、「基本的にChatGPTのモデルでは、ファインチューニングがあまり効かないことが分かってきました」と言うのは、アシスト DX推進技術本部 AI技術部 部長の佐藤彰広氏だ。モデル本体がインターネット上の膨大なデータを学習したことを優先しがちで、少ない量のデータを使いチューニングをしても、回答の精度があまり上がらないと考えられた。

ファインチューニングでも回答精度が上がらないため、この時点でサポート業務での生成AI活用プロジェクトは、行き詰まりを見せた。
Glean活用でサポート業務効率化、高度化へ
ちょうどその頃、アシストが扱うエンタープライズサーチエンジン「Glean」に生成AI機能が追加され、プロジェクトで先行利用できることとなる。これが、状況を大きく変えた。
アシストでは、GleanでGoogle Driveなどにある社内技術ナレッジを参照可能にしていた。それに加え、FAQやサポートナレッジの新旧管理システムにもGleanからアクセスできるように設定する。これにより、社内ナレッジを活用した生成AIによる回答生成が可能となり、回答精度は劇的に向上したのだ。
GleanはRAGと同様の仕組みで、質問に関連する社内ナレッジをセキュアにAzure OpenAIに提供し、回答の生成を支援できる。これにより、信頼性の高い情報に基づく回答が可能となり、ハルシネーションも抑制できる。結果として、サポート担当者の業務は、かなり効率化すると確認できた。
FAQレベルの質問であれば高い精度で回答できることが分かり、サポート業務の効率化が実現できることが分かる。そこで効率化に加え、顧客理解向上と新たな付加価値提供を目指し、サポート業務の高度化にも着手する。
サポートセンターでは、問い合わせ対応後に顧客アンケートを実施し、6つの評価項目から対応の総合満足度を測定している。回答までの時間よりも、問い合わせの背景や意図を理解した対応のほうが顧客満足度に大きく影響することが分かっていた。顧客理解には、過去の問い合わせ内容、所属や属性、アンケート結果などが役立つ。
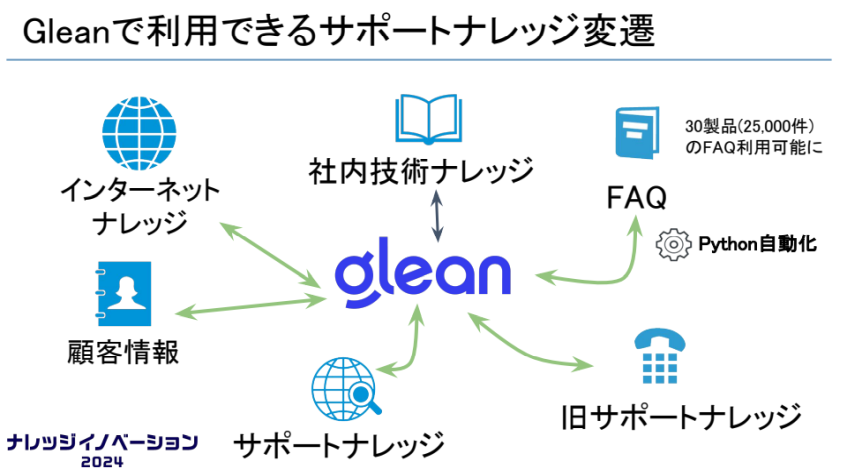
そこで、Gleanを活用し、過去の対応履歴、アンケートの指摘事項、顧客情報などを生成AIで分析し、担当者が容易に参照できる仕組みを構築する。これにより、過去の顧客コメントなどを基にした改善提案が、事前に得られるようになった。「顧客からのコメントなども蓄積されており、それをGleanが読み取って、過去にこのような指摘があったのでこう改善したほうがいいとの情報を、事前に教えてくれます」と平氏は言う。
問い合わせ対応前にGleanで顧客に関する情報を分かりやすく参照することで、過去の指摘事項などを把握し、顧客に合わせた回答が可能となる。この仕組みを使うようになり、サポート担当者では顧客理解を重視したサポートが浸透しつつある。
Gleanを使った仕組みでは、サポートナレッジや顧客情報、アンケート結果などを基にフィードバックを提供する。担当者は顧客情報を入力するだけで、プロンプトを通じて適切な情報を参照し、顧客背景に応じた対応が可能となる。これら一連の処理をアプリケーション化したことで、得られる情報の均質化も実現している。
これまでも、アンケートの結果で顧客から改善点の指摘などがあれば、担当者がマネージャーとレビューを行うなどの対応はしていた。同じ担当者が対応すれば、過去に指摘されたポイントも、その後のレビューも記憶しているかもしれない。しかし、それをチームで共有するのは難しかった。
今回のGleanの仕組みでは、そういったレビューの結果なども踏まえてフィードバックが得られる。「顧客に対する理解度は、確実に向上されています」と土井氏も言う。
RAG構築の課題を克服、Gleanが生成AI活用を加速
2023年夏頃には、Gleanの活用で回答精度が向上した。それは、RAGへの注目が高まり始めた頃でもある。そこでアシストでは、Glean以外でも生成AIの活用を模索している。同年10月頃にはAmazon Bedrockを用いたRAGの検証も実施した。
この時のRAGの検証結果を佐藤氏は、「さまざまな情報が含まれる広範なサポートのナレッジ情報に対し、ベクターデータベースとセマンティックサーチの仕組みを構築するのは、容易ではありません。ベクターデータ・ビューを50個くらい作り、それらを適宜切り替えて利用するとなれば、運用が耐えられません」と語る。日々問い合わせケースは増え、それらの情報全てをベクトルデータベースに取り込むのも簡単ではない。実現しようとすれば、多くのエンジニアが貼り付き対応しないと実現できない仕組みになりかねない。
一方、Gleanはコンテンツのベクトル化やセマンティックサーチが高度に作り込まれており、エンジニアの負担を軽減し、生成AIへのナレッジ活用を容易にしている。Gleanは文章内容だけでなく、作成者や利用頻度などの情報も活用する。既存のアルゴリズムにより、高度な作り込みなしに関連情報を抽出し生成AIに提供することで、回答精度の向上をもたらすと考えられる。これが実現できているのは、Gleanが生成AI登場前から、社内ナレッジの活用を追求してきた製品だからだと佐藤氏は分析する。
アシストでは、サポートセンター全体にGleanの生成AI活用を展開している。検証した3製品では、Gleanの利用により問い合わせのクローズ率が向上した。当初はGlean利用グループと非利用グループに分け効果を明確に測定する計画もあったが、社内でGleanの良い評判が広まり、利用の要望の声が多く検証は実施できなかった、と土井氏は振り返る。
生成AIの活用は、質問の回答支援、顧客の背景理解などだけでなく調査などにも適用範囲を広げている。サンプルデータの作成、SQLやHTMLのエラーの調査などでは、かなり精度の高い回答が得られるようになっている。
アシストでは、サポート管理画面からGleanを直接起動し、業務プロセスに組み込むことで誰もが活用しやすくしている。また、継続的な生成AIの回答精度向上のために、プロンプト調整をカスタマイズ画面で頻繁に行えるようにもしている。今後はこれらの経験を踏まえて、Gleanによる自社ナレッジ活用の提案を顧客向けにも進める。
LLMは日々進化しており、企業が生成AIを活用するには、RAGによる社内情報連携が鍵となる。RAGの仕組みをオープンソースのツールなどを組み合わせて、自由にカスタマイズしながら自社に最適化することはできる。しかしそれには、それなりの技術リソースとノウハウが必要だろう。今後は、Gleanのような仕組みを活用し、自社に合ったRAGの仕組みを、なるべく手間をかけずに実現するのが、企業における生成AI活用のトレンドとなりそうだ。
